
- August 12, 2015
- Posted by: Surender Kumar
- Category: Windows Server
Domain Name System
Table of Contents
The Domain Name System (DNS) is a hierarchical distributed naming system for computers, services, or any resource connected to the Internet or a private network. DNS translates domain names, which can be easily memorized by humans, into the numerical IP addresses needed for the purpose of computer services and devices worldwide.
DNS stores the information into records. The most common types of records stored in the DNS database are Start of authority record (SOA), host record (A and AAAA), SMTP mail exchangers record (MX), name servers record (NS), pointers for reverse DNS lookups (PTR), and domain name aliases (CNAME). A DNS server or name server is a server that stores the DNS records for a domain name. A DNS server responds with answers to queries against its database. An authoritative name server is a name server that gives answers that have been configured by an original source, for example, the domain administrator or by dynamic DNS methods, in contrast to answers that were obtained via a regular DNS query to another name server. An authoritative-only name server only returns answers to queries about domain names that have been specifically configured by the administrator.
DNS primarily uses User Datagram Protocol (UDP) on port number 53 to serve requests. DNS queries consist of a single UDP request from the client followed by a single UDP reply from the server. The Transmission Control Protocol (TCP) port number 53 is used when the response data size exceeds 512 bytes, or for other tasks such as zone transfers.
Relationship between DNS and ADDS
When implementing Active Directory within your environment, DNS is required. Active Directory cannot exist without it. Although you are not required to use Microsoft’s implementation of DNS; UNIX BIND (Berkeley Internet Name Domain) will also work just fine as long as it meets certain criteria.
The DNS and ADDS are like Train and Railway track. The train’s engine is mighty-powerful that can pull thousands of tons of equipment, but without the railway track, it cannot move. If the track is not aligned correctly, the train may derail. If the track is not switched in the right direction, the train will not arrive at the correct destination. The DNS and Active Directory works in the same way.
Looking at the correlation between your Active Directory and DNS, you will find the two share the same zone-naming conventions. If your Active Directory domain name is airvoice.local, the DNS namespace will also be airvoice.local. Notice that the top-level domain (TLD) name for DNS, in this case local, does not have an equivalent domain within Active Directory. That is because, for most companies, the top-level domain is not unique and is not owned by the company. Take for instance a company that is using techtutsonline.com as its Active Directory namespace. The TLD used in this case (com) is owned by the Internet Corporation for Assigned Names and Numbers (ICANN) and is shared by hundreds of thousands of Internet-based websites. When designing Active Directory, the designers decided to make sure that the root of the Active Directory forest could be unique; they required the domain names to take on two domain components: the company’s DNS domain and the TLD that it resides under.
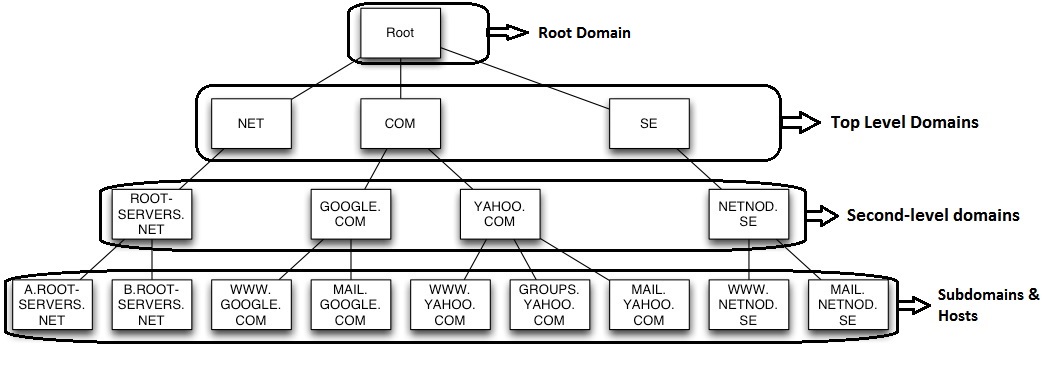
As a domain controller comes online, part of its startup routine is to attempt registration of the SRV records that identify the services that are running on the domain controller. The only requirement for a DNS server to work with Active Directory is that the DNS server support SRV records. It does not matter to Active Directory clients if the records are entered manually by an administrator or automatically by the domain controller itself; all that matters is that the records are correct. If the SRV records are not listed within the zone or are entered incorrectly, the client will not be able to locate the domain controller. If the SRV records are correctly listed within the DNS zone, the host name of the server that is providing the service is returned to the client. The client will then query the DNS server for the A record (hostname record) of the domain controller to resolve the IP address.
Name Resolution Process
The client side of the DNS is called a DNS resolver. A resolver is responsible for initiating and sequencing the queries that ultimately lead to a full resolution (translation) of the resource, e.g., translation of a domain name into an IP address. This sequence may be recursive or iterative, or a combination of both. Domain name resolvers determine the domain name servers responsible for the domain name in question by a sequence of queries starting with the right-most (top-level) domain label.
Forward Name Resolution: It is the process which resolves a user-friendly domain name into an IP address. The request is called forward lookup query.
Reverse Name Resolution: It is the process which resolves an IP address to a user-friendly domain name. The request is called reverse lookup query.
Recursive Query: In a recursive name query, the DNS client requires that the DNS server respond to the client with either the requested resource record or an error message stating that the record or domain name does not exist. The DNS server cannot just refer the DNS client to a different DNS server. Thus, if a DNS server does not have the requested information when it receives a recursive query, it queries other servers until it gets the information, or until the name query fails.
Iterative Query: An iterative name query is one in which a DNS client allows the DNS server to return the best answer it can give based on its cache or zone data. If the queried DNS server does not have an exact match for the queried name, the best possible information it can return is a referral (that is, a pointer to a DNS server authoritative for a lower level of the domain namespace). The DNS client can then query the DNS server for which it obtained a referral. It continues this process until it locates a DNS server that is authoritative for the queried name, or until an error or time-out condition is met.
For proper operation of its domain name resolver, a network host is configured with an initial cache (hints) of the known addresses of the root name servers. The hints are updated periodically by an administrator by retrieving a dataset from a reliable source. The resolution process starts with a query to one of the root servers to find the server authoritative for the top-level domain. The obtained TLD server is queried for the address of a DNS server authoritative for the second-level domain. Iteratively, each domain name label is used to query the resulting server of the previous step until the final step returns the IP address of the host name to be resolved. The diagram illustrates this process for the host www.techtutsonline.com.
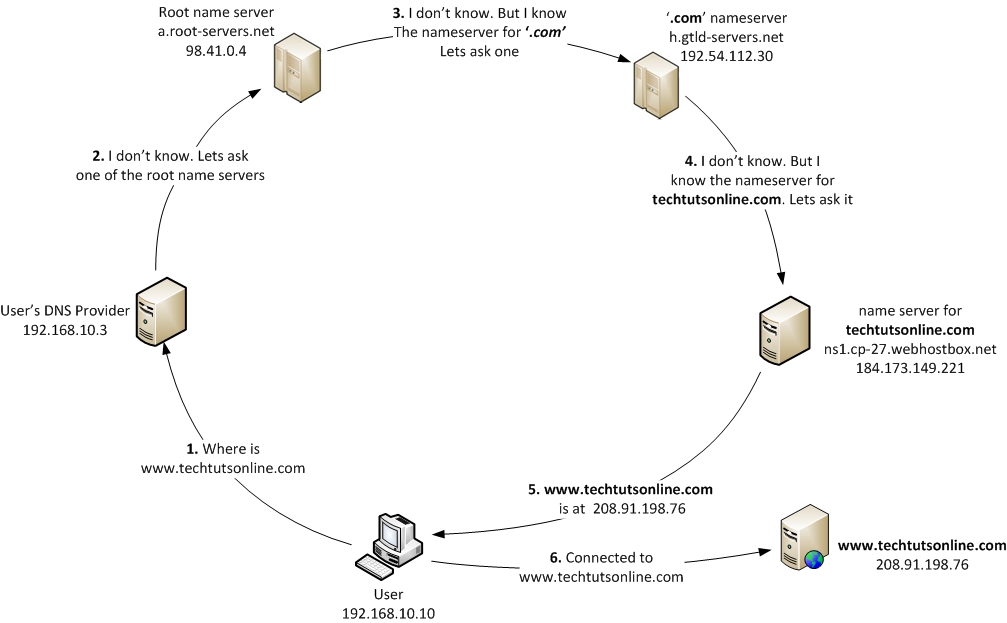
This mechanism would place a large traffic burden on the root servers, as every resolution on the Internet would require them. In practice caching is used in DNS servers to off-load the root servers, and as a result, root name servers actually are involved in only a fraction of all requests.
Caching Name Server
The Domain Name System supports DNS cache servers which store DNS query results for a period of time determined in the configuration (time-to-live) of the domain name record in question. Typically, such caching DNS servers, also called DNS caches, also implement the recursive algorithm necessary to resolve a given name starting with the DNS root through to the authoritative name servers of the queried domain. With this function implemented in the name server, user applications gain efficiency in design and operation.
DNS Record Types
Below is the list of DNS record types permissible in zone files of the Domain Name System (DNS).
A Records
The address (A) or resource record or Host record maps an FQDN to an IP address, so the resolvers can request the corresponding IP address for an FQDN. For example, the following A resource record, located in the zone zone1.techtutsonline.com, maps the FQDN of the server to its IP address:
dc1 IN A 208.91.198.76
For IPv6, it is known as AAA record.
PTR Records
The pointer (PTR) resource record , in contrast to the A resource record, maps an IP address to an FQDN. For example, the following PTR resource record maps the IP address of dc1.techtutsonline.com to its FQDN:
76.198.91.208.in-addr.arpa. IN PTR dc1.techtutsonline.com.CNAME Records
The canonical name (CNAME) resource record creates an alias (synonymous name) for the specified FQDN. You can use CNAME records to hide the implementation details of your network from the clients that connect to it. For example, suppose you want to put an FTP server named ftp1.techtutsonline.com on your techtutsonline.com domain, but you know that in six months you will move it to a computer named ftp2.techtutsonline.com, and you do not want your users to have to know about the change. You can just create an alias called ftp.techtutsonline.com that points to ftp1.techtutsonline.com, and then when you change your FTP server, you need to only change the CNAME record to point to ftp2.techtutsonline.com. For example, the following CNAME resource record creates an alias for ftp1.techtutsonline.com:
ftp.techtutsonline.com. IN CNAME ftp1.techtutsonline.com.Once a DNS client queries for the A resource record for ftp.techtutsonline.com, the DNS server finds the CNAME resource record, resolves the query for the A resource record for ftp1.techtutsonline.com, and returns both the A and CNAME resource records to the client.
MX Records
The mail exchange (MX) resource record specifies a mail exchange server for a DNS domain name. A mail exchange server is a host that will either process or forward mail for the DNS domain name. Processing the mail means either delivering it to the addressee or passing it to a different type of mail transport. Forwarding the mail means sending it to its final destination server, sending it using Simple Mail Transfer Protocol (SMTP) to another mail exchange server that is closer to the final destination, or queuing it for a specified amount of time.
If you want to use multiple mail exchange servers in one DNS domain, you can have multiple MX resource records for that domain. The following example shows MX resource records for the mail servers for the domain techtutsonline.com.:
*.techtutsonline.com. IN MX 0 mail1.techtutsonline.com.
*.techtutsonline.com. IN MX 10 mail2.techtutsonline.com.The first three fields in this resource record are the standard owner, class, and type fields. The fourth field is the mail server priority , or preference value. The prference value specifies the preference given to the MX record among MX records. Lower priority records are preferred. Thus, when a mailer needs to send mail to a certain DNS domain, it first contacts a DNS server for that domain and retrieves all the MX records. It then contacts the mailer with the lowest preference value.
For example, suppose John sends an e-mail message to [email protected] on a day that mail1 server is down, but mail2 server is working. His mailer tries to deliver the message to mail1, because it has the lowest preference value, but it fails because mail1 is down. This time, John’s mailer will deliver the message to mail2 server. It successfully delivers the message to mail2 because it is working.
SOA Records
Every zone contains a Start of Authority (SOA) resource record at the beginning of the zone. SOA resource records include the following fields:
-
The Owner , TTL , Class , and Type fields, as described in “Resource Record Format” earlier in this chapter.
- The authoritative server field shows the primary DNS server authoritative for the zone.
- The responsible person field shows the e-mail address of the administrator responsible for the zone. It uses a period (.) instead of an at symbol (@).
- The serial number field shows how many times the zone has been updated. When a zone’s secondary server contacts the master server for that zone to determine whether it needs to initiate a zone transfer, the zone’s secondary server compares its own serial number with that of the master. If the serial number of the master is higher, the secondary server initiates a zone transfer.
- The refresh field shows how often the secondary server for the zone checks to see whether the zone has been changed.
- The retry field shows how long after sending a zone transfer request the secondary server for the zone waits for a response from the master server before retrying.
- The expire field shows how long after the previous zone transfer the secondary server for the zone continues to respond to queries for the zone before discarding its own zone as invalid.
-
The minimum TTL field applies to all the resource records in the zone whenever a time to live value is not specified in a resource record. Whenever a resolver queries the server, the server sends back resource records along with the minimum time to live. Negative responses are cached for the minimum TTL of the SOA resource record of the authoritative zone.
The following example shows the SOA resource record:
techtutsonline.com. IN SOA (
dc1.techtutsonline.com. ; authoritative server for the zone
admin.techtutsonline.com. ; zone admin e-mail
; (responsible person)
5099 ; serial number
3600 ; refresh (1 hour)
600 ; retry (10 mins)
86400 ; expire (1 day)
60 ) ; minimum TTL (1 min)NS Records
The name server (NS) resource record indicates the servers authoritative for the zone. They indicate primary and secondary servers for the zone specified in the SOA resource record, and they indicate the servers for any delegated zones. Every zone must contain at least one NS record at the zone root.
For example, when the administrator on techtutsonline.com delegates authority for the chd.techtutsonline.com subdomain to dc1.chd.techtutsonline.com., the following line will be added to the zones techtutsonline.com and chd.techtutsonline.com:
techtutsonline.com. IN NS dc1.chd.techtutsonline.com.SRV Records
With MX records, you can have multiple mail servers in a DNS domain, and when a mailer needs to send mail to a host in the domain, it can find the location of a mail exchange server. But what about other applications, such as the World Wide Web or telnet?
Service (SRV) resource records enable you to specify the location of the servers for a specific service, protocol, and DNS domain. Thus, if you have two Web servers in your domain, you can create SRV resource records specifying which hosts serve as Web servers, and resolvers can then retrieve all the SRV resource records for the Web servers.
The format of an SRV record is as follows:
_Service._Proto.Name TTL Class SRV Priority Weight Port Target
- The _ Service field specifies the name of the service, such as http or telnet. Some services are defined in the standards, and others can be defined locally.
- The _ Proto field specifies the protocol, such as TCP or UDP.
- The Name field specifies the domain name to which the resource record refers.
- The TTL and Class fields are the same as the fields defined earlier in this chapter.
- The Priority field specifies the priority of the host. Clients attempt to contact the host with the lowest priority.
- The Weight field is a load balancing mechanism. When the priority field is the same for two or more records in the same domain, clients should try records with higher weights more often, unless the clients support some other load balancing mechanism.
- The Port field shows the port of the service on this host.
-
The Target field shows the fully qualified domain name for the host supporting the service.
The following example shows SRV records for Web servers:
_http._tcp.techtutsonline.com. IN SRV 0 0 80 webserver1.techtutsonline.com.
_http._tcp.techtutsonline.com. IN SRV 10 0 80 webserver2.techtutsonline.com.DNS Zones
The domain name space of the Internet is organized into a hierarchical layout of subdomains below the DNS root domain. The individual domains of this tree may serve as delegation points for administrative authority and management. However, usually it is furthermore desirable to implement fine-grained boundaries of delegation, so that multiple sub-levels of a domain may be managed independently. Therefore the domain name space is partitioned into areas (zones) for this purpose. A zone starts at a domain and extends downward in the tree to the leaf nodes or to the top-level of subdomains where other zones start.
The DNS Server provides four types of zones:
- Primary zone
- Primary Read-Only Zone
- Secondary zone
- Stub zone
Primary Zone
Primary zones have traditionally been held on a single system and are known in the Microsoft world as standard primary zones. Primary zones are the update points within DNS. The limitation to these zones is their inherent single point of failure. Although the zone data can be transferred to another server that acts as the secondary zone, if the server that holds the primary zone is unavailable, you cannot make changes to the zone. In this case, you must promote a secondary zone to primary if you need to make updates to the zone. When the zone is stored in a file, by default the primary zone file is named zone_name.dns and it is located in the %windir%\System32\dns folder on the server. Administrator can directly modify the data stored in Primary Zone.
Another limitation to standard primary zones stems from the single update point. When using clients that support dynamic DNS updates, the only server in the zone that can receive the updates is the one holding the primary zone.
Primary Read-Only Zone
With the introduction of the read-only domain controller (RODC), Windows Server 2008 also introduced the primary read-only zone.
An RODC with a primary read-only zone configured will receive a read-only copy of the following application directory partitions in the domain:
- The domain partition
- ForestDNSZones
- DomainDNSZones
This allows the secure RODC to have a very secure read-only copy of the DNS information in the domain. From the RODC, you can view the contents of the primary read-only zone, but you can make changes to only the zones that are located on DNS servers that host the primary zones.
Secondary Zone
Secondary zones have been around as long as primary zones. When an administrator wanted another DNS server to host the same zone information as the primary zone, a secondary zone would be created, which would host identical information as on the primary zone. The zone data within a secondary zone is a read-only copy of the primary zone database.
Secondary zones still have their place within an organization. If you have a remote location where you do not want to support a domain controller but you want to provide local resolution to the clients, you can create a secondary zone on a server within that location. This will reduce the amount of query traffic that has to pass across the WAN link, but you will be required to send zone transfers from a master server across the WAN link to the secondary zone. Typically, there will be more queries sent by clients than there will be dynamic updates from clients. Even so, you should monitor the traffic that is passing across the WAN link to determine if you are using the link appropriately.
Stub Zone
Stub zones do not contain all of the resource records from the zone, as the primary and secondary zone types do. Instead, only a subset of records populates the zone, just enough to provide the client with the information necessary to locate a DNS server that can respond to a query for records from the zone.
When you create the stub zone, it is populated with the SOA record along with the NS records and the A records that correspond to the DNS servers identified on the SOA record. All this is done automatically. The administrator of the zone is not required to create the SOA, name server (NS), or A records. Instead, as the zone is created, the DNS server will contact a server that is authoritative for the zone and request a transfer of those records. Once populated, the DNS server holding the stub zone will contact the authoritative server periodically to determine if there are any changes to the SOA, NS, and A records. You can control how often the DNS server requests updates by configuring the refresh interval on the SOA record for the zone.
DNS Zone Transfers
To have an effective DNS solution, you need to make sure that the clients have access to a local DNS server. To have DNS servers close to the clients, you will probably need to propagate the zone data to DNS servers in several locations. This is accomplished by using zone transfers.
Zone transfers come in two flavors: authoritative zone transfers (AXFRs) and incremental zone transfers (IXFRs). An AXFR, sometimes referred to as a complete zone transfer, transfers the entire zone database when the zone transfer is initiated. An IXFR, as defined in RFC 1995, transfers the changes in the zone only since the last zone transfer. The amount of data that is transferred during an IXFR could be substantially less than that of an AXFR.
The choice to use zone transfers is usually made because the DNS servers in your environment are not Windows 200x–based. Third-party DNS servers do not participate in Active Directory replication, nor can they read the Active Directory database to determine the resource records that are used. To keep the network usage as low as possible, make sure the DNS servers all support IXFR. Otherwise, every time a zone transfer is initiated, the complete zone records will be passed to all of the appropriate DNS servers.
Active Directory–integrated zones can take advantage of Active Directory replication to propagate the changes made to resource records. When you use Active Directory replication, not only do you have the additional benefit of having only one replication topology, but the amount of data usually passed across the network is smaller. For instance, take a record that changes a couple of times before the replication or zone transfer occurs. In the case of a zone transfer, if the record changes twice before the transfer is initiated, both changes have to be sent even if some of the data is no longer valid. In the case of Active Directory replication, only the effective changes are replicated. All of the intermediate changes are discarded.
You also gain the advantage of the built-in functionality of replication. Replication traffic between domain controllers is compressed to reduce network overhead. This is significant when you consider an environment where you have multiple sites, many of which could be connected through WAN links. If there are considerable amounts of zone information to be transferred, the replication traffic that is sent between domain controllers in different sites is compressed.
Active Directory–integrated zones boast the benefit of being able to share the responsibility of updating the zone, whether it is from dynamic DNS clients or via manually entered records. The single point of administration and single point of failure disappear. There are, however, limitations to using Active Directory–integrated zones.
Securing the DNS Server
DNS has been a popular service to attack because so many clients rely on it to locate the host systems they are attempting to contact. Without DNS, you would not be able to locate www.techtutsonline.com. You could call the web server by its IP address, but you can not remember hundreds of IP addresses.
Two methods of attack are usually attempted against DNS servers: denial-of-service (DoS) attacks, and abusing the name resolution. In the beginning I used an analogy that compared DNS to railway tracks. When someone attacks DNS, they are essentially attempting to derail or misguide our trains by adversely affecting the tracks. With denial-of-service attacks, the attacker attempts to block the DNS server from answering client queries, thereby derailing the clients. When abusing the name resolution that a DNS server provides, the attacker either will cause the DNS server to return incorrect results to the client or will gather information about a company from the data that the DNS server returns. This method does not stop the DNS service from responding to the clients; it simply misdirects them, sending them to the wrong destination.
Understanding just how important DNS is to a company’s infrastructure, the designers of DNS built the service to be redundant and able to withstand attacks that attempt to take down the DNS servers that support a company. Nevertheless, some attackers will try to knock down your DNS so that they can reduce the effectiveness of your implementation, annoy your clients as they attempt to perform their jobs, and just plain dampen your spirits. Denial-of-service attacks can be devastating, but you can take steps to put yourself at ease. The following sections cover practices you should take into account when you are designing your DNS infrastructure.
Limit the Dynamic Updates
I am going to assume that you are working in an Active Directory environment, because that is the main thrust of this book. An Active Directory–integrated DNS server can be configured so that it accepts dynamic update requests only from authorized systems. Once you configure a zone as Active Directory–integrated, you should change the dynamic updates so that only secure updates are allowed. At that point, only members of Active Directory can update the zone records. Once secure updates are turned on, an attacker will not be able to easily add to your database false records that could cause the domain controller to become overloaded as it tries to replicate the changes.
In a Windows Server 2003 or 2008-based domain, you can take this one step further by making sure that the DNS data is replicated only to domain controllers that are DNS servers or by specifying that the records are replicated only to the DNS servers that are included within the scope of an application partition.
Monitor for Traffic
If the DNS server appears to be overloaded and you believe the resource overhead is due to an attack, you can use a monitoring tool, such as Microsoft’s Network Monitor or a product such as Sniffer, to detect where the traffic is originating. If the traffic is from outside of your company, you can assume that you are being attacked. If this is the case, you can attempt to quell the traffic by putting firewall rules into place that will reject packets that originate from the addresses that you identify from the network trace. Most firewalls can be configured to drop spoofed packets. Check with your firewall administrator to determine what you can do with the firewalls in your infrastructure.
Putting rules into place does not mean you will stop the attack. The attacker was probably spoofing his or her address in the first place, so you may end up being attacked again from the same entity but through another address. Some firewalls have intrusion-detection capabilities, and you may be able to have the firewall dynamically drop packets if they are deemed an attack. You should develop a plan for monitoring the traffic that enters your network, whether or not it is bound for DNS. This plan should take into account the necessity of watching for attack types as well as determining how much monitoring you should perform so that it does not adversely affect the network performance.
The DNS monitoring policy should include references to who will be responsible for designing the monitoring solution, who will implement the policy, where the settings will be applied, and who will be responsible for reviewing the data that is collected.
Set Quotas
In Windows Server 2003 and 2008-based Active Directory domains, you have the ability to set quotas on the number of objects a user is allowed to create within the Active Directory partitions. You can set quotas differently on each Active Directory partition because each partition is evaluated separately. By using quotas you are able to effectively control the number of objects that can be created by an account, thereby quelling any attempt to flood an Active Directory–integrated zone with too many false objects.
You can set a quota limit on either user accounts or group accounts. An account that has been explicitly added to the quota list and is a member of a group that has quotas applied to it will be able to create as many objects as the least restrictive of the quota policies will allow. When a user attempts to create an object within the container where a quota limit has been set, the existing objects are compared against the quota limit. If the user has not met the quota, the object can be created, but the user will be denied the ability to create the object if the quota has been met.
The command dsadd is used to create a quota limit for an Active Directory partition. You can set quotas on any of the partitions, schema, configurations, domains, or any application partitions. However, the quota can be created or modified only on a Windows Server 2003 or 2008 domain controller, because Windows 2000 domain controllers are unfamiliar with the command-line utilities used to work with the Active Directory partitions.
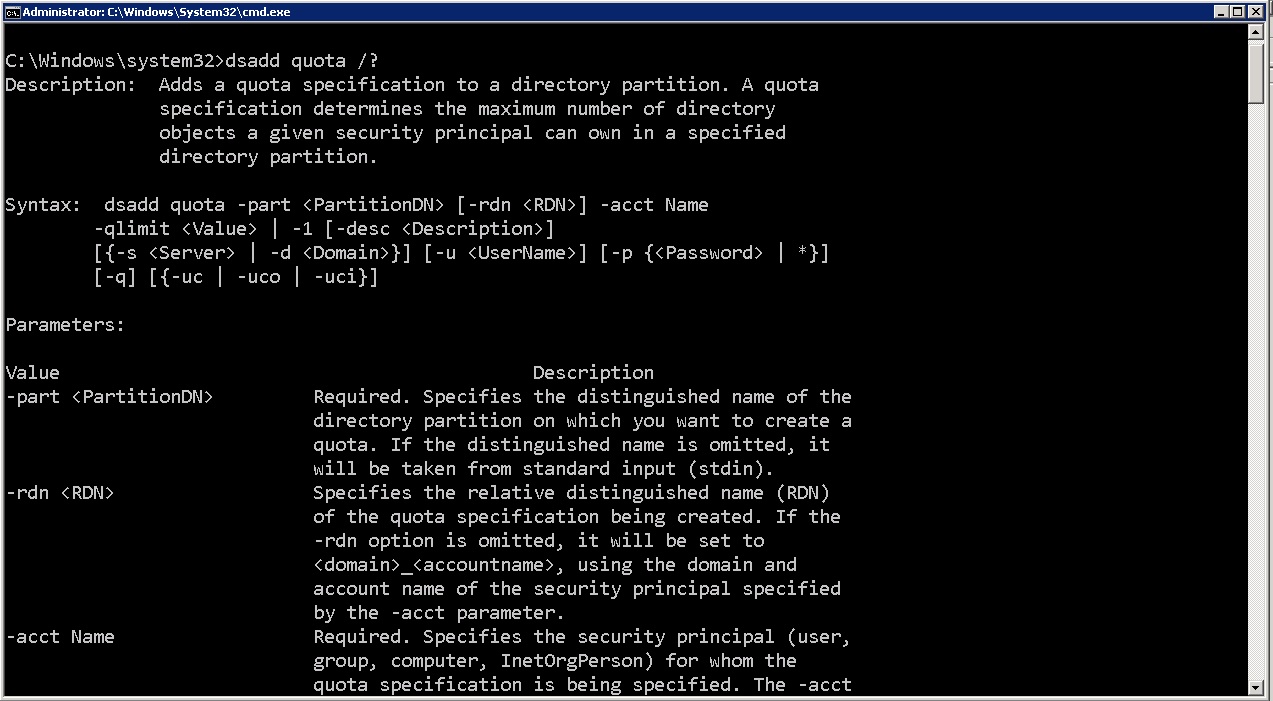
quota command
If at a later time you want to modify the number of objects that specific user could create, you could use the dsmod quota command.
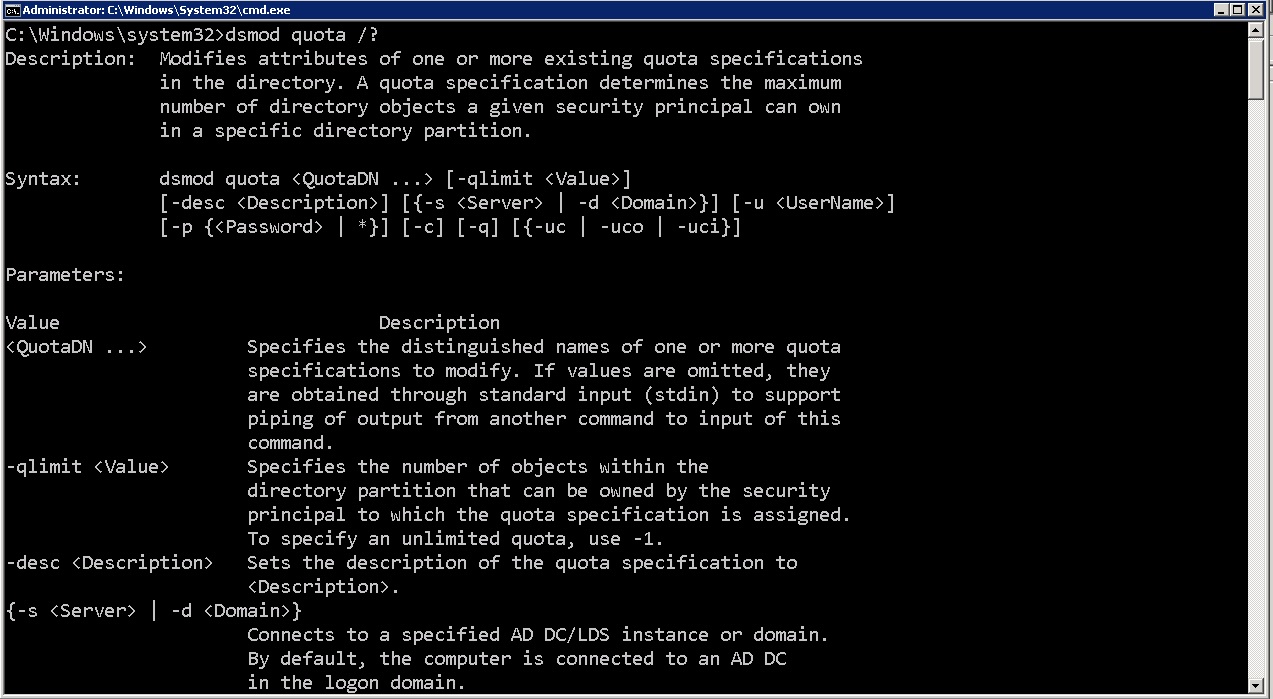
quota command
Disable Recursion
The typical behavior for a DNS server is to take over the name-resolution process whenever a client is attempting to resolve a host name. Clients typically send an iterative query to their DNS server, and the DNS server starts the recursion process to locate a DNS server that can identify the IP address for the host name in question. An attacker can take advantage of this scenario and start attacking the DNS server with several queries in an attempt to limit its ability to respond to valid queries.
When you disable recursion on a DNS server, you are essentially telling the DNS server that it will no longer be a slave to the client, and it should only return a referral to the client. In this scenario, the DNS server takes on a far smaller load, but the client will incur more of the work. As the clients send queries to their DNS servers, the DNS servers will check their zone data for a match. If the DNS server is not authoritative for the zone and has not cached the entry, the DNS server will refer the client to another DNS server to contact.
To disable recursion, open the properties of the DNS server, go to Advanced Tab and select the option Disable Recursion (Also Disables Forwarders), as shown in diagram below:
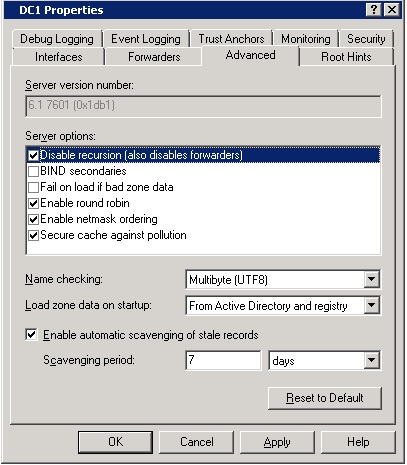
Avoid Cache Poisoning
An attacker could attempt to populate the cache on your DNS server with incorrect information in an attempt either to stop name resolution or to redirect clients to incorrect systems. If an attacker were able to populate the cache with an entry that would redirect a client to the wrong DNS server, the client could receive a response to their query that redirected them to a compromised host.
To make sure the entries within the DNS cache are complete and accurate entries that are part of the name-resolution path the DNS server has obtained during resolution, you can enable the Secure Cache against Pollution option, as seen in Figure 2.14. You can reach this option by opening the properties of your DNS server and selecting the Advanced tab.
During normal query operations, DNS servers will query other DNS servers to resolve the query. If a DNS server holds the correct information in cache, it can respond with a complete answer to the query, but it is not the authoritative server. Why not? Because if someone wants to cause a misdirection, they could enter information into the DNS server’s cache, which would in turn give wrong data back to all other DNS servers that are using that DNS server to resolve. Once this option is enabled, your DNS server will ignore records that were not obtained from the DNS server that is authoritative
for the zone in question. This will place additional resource requirements on your DNS server: it will need to perform more queries due to the dropping of records that are not obtained from authoritative DNS servers. However, this method guarantees the authenticity and accuracy of the records.
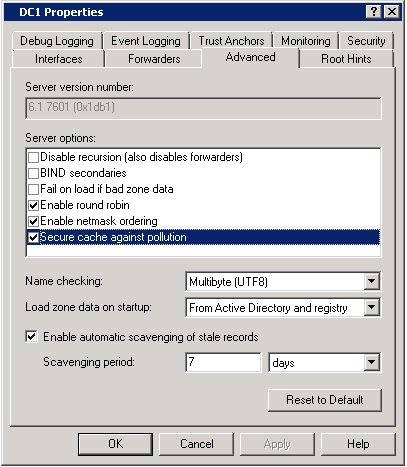
cache pollution
1 Comment
Comments are closed.
Great article.